Introduction
InfoWorld defines Apache Spark as a data processing framework that can quickly perform processing tasks on very large data sets, and can also distribute data processing tasks across multiple computers, either on its own or in tandem with other distributed computing tools (Source: InfoWorld).
Apache Spark – The Go-To Data Analytics Engine
Apache Spark is an open-source unified analytics engine, used for distributed processing for big data workloads. It employs optimized query execution and in-memory caching for fast analytic queries for data of any size. Spark has a RDDs a.k.a Resilient Distributed Datasets, which is nothing but a rigid distributed collection of elements of your data. And the in-memory data structure allows it to perform functional programming. It uses a DAG scheduler along with a physical execution engine and the query optimizer.
The beauty of Spark is that it can process big data sets quicker by dividing the work into small chunks and assigning them over computational resources.
Is Apache Spark the only data processing engine available? Do we have other options? Well indeed, which we are going to explore a little bit in the next section.
Alternatives Of Apache Spark
Data processing are an ocean and many want to have a piece of the pie. Some of the well-known competitors to Apache Spark are listed below.
Google BigQuery
Google themselves defines BigQuery as a “Serverless, highly scalable, and cost-effective multi-cloud data warehouse designed for business agility”. A Platform as a Service business that offers ANSI SQL to query.
Amazon Kinesis
Amazon Kinesis is one of the best products in Amazon’s toy chest. Amazon claims that it collects, processes, and analyzes real-time, streaming data to get timely insights and react quickly to new information.
Google Cloud Dataflow
A part of the Enterprise Google Analytics 360 suite, Google Cloud Dataflow helps is creating powerful and actionable dashboards for data-driven decision-making.
Apache Storm
Apache Storm is a distributed stream processing computation framework written predominantly in the Clojure programming language. (Source: Apache Storm)
Elasticsearch
In Elasticsearch’s own words “Elasticsearch is a distributed, free and open search and analytics engine for all types of data, including textual, numerical, geospatial, structured, and unstructured. Elasticsearch is built on Apache Lucene.” (Source: Elasticsearch)
Now that we have discussed the alternatives to Apache Spark, the next question is “What makes Apache Spark special?” and we will answer that in the next section.
The Secret Sauce To Making Apache Spark Stand Out
A key point that makes Apache Spark a favorite amongst data analysts across the globe is its speed. The need for speed in the world of data is highly desirable but few engines achieve it, Apache Spark is a key player there.
The speed it has for querying, analyzing, and transforming big data ranks topmost in our list of desirable characteristics. But it doesn’t end there.
- It is great for iterative algorithms as it analyses the previous estimate through a new set of estimations
- It takes the cake with its set of easy to use APIs reducing the complexity of development, readability, and maintenance
- It can integrate with other products and can handle multiple languages
- It helps in making complex data pipelines coherent and easy to read
Many have heard that Apache Hadoop is also a great alternative to Spark. Well, we try to categorically compare and show the differences between the two data analytics engines for you to make a more informed decision.
The Battle Of The Giants – Apache Spark Vs Hadoop Systems
Apache Hadoop is another open-source framework that helps in big data processing. This framework uses MapReduce techniques to split the data as blocks and assign them to cluster nodes across. It is a file-based system (HDFS) and operates on physically written files to process chunks of data in cluster nodes.
| Area for Comparison | Apache Spark | Apache Hadoop |
| Performance | Since Spark uses RAM to process it is extremely faster. Uses RDD to process. | Since Hadoop uses disk storage to process comparatively slower. |
| Cost | Cost of Memory is more than the storage system and it is expensive. | Storage is less expensive. |
| Data Processing | Good for both batch and live stream data processing. | Best of batch processing. No Stream processing is supported by Hadoop. |
| Ease of Use and Language Support | More difficult to use with less supported languages. Uses Python or Java for MapReduce apps. | More user-friendly. Allows interactive shell mode. APIs can be written in Java, Scala, R, Python, and Spark SQL. |
| Machine Learning | Much faster with in-memory processing. Uses MLlib for computations. | Slower than Spark. Bottlenecks can be created due to large Data fragments. Mahout is the main library. |
| Scheduling and Resource Management | Uses external solutions. YARN is the most common option for resource management. | Has built-in tools for scheduling, resource allocation, and monitoring. |
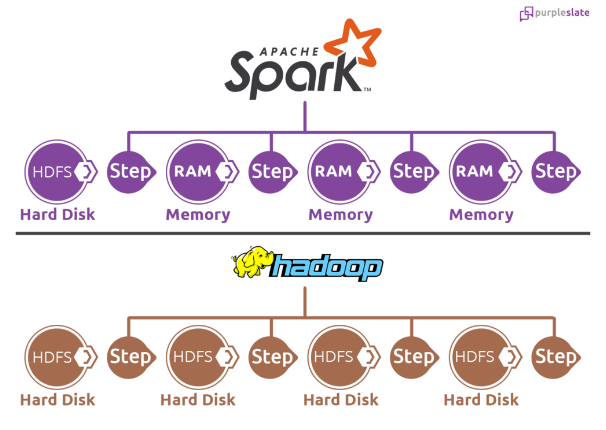 Sparks vs Hadoop
Sparks vs HadoopVerdict – Apache Spark is a More Preferred Data Analytics Engine
As you could see in the Hadoop system output of the step is written to the Hard System HDFS and it is sequenced to the next step. However, Spark handles everything in Memory and is not sequenced. All its transformation and actions are done in parallel using the DAG scheduler and hence it makes it faster than the HDFS system.
Stay tuned folks, as next in the series, we will discuss how the entire Apache Spark system is designed.