
Hello, RAG!
Retrieval Augmented Generation, abbreviated as RAG, empowers Large Language Models (LLMs) by incorporating information retrieved from a data source to anchor its generated responses. In essence, RAG combines search capabilities with LLM prompting, enabling users to request the model to answer queries based on information gleaned through a search algorithm. The query and the retrieved context are integrated into the prompt sent to the LLM, facilitating a more informed and contextually grounded response.
RAG is the dominant architecture for Large Language Model (LLM) systems, with numerous products relying heavily on its capabilities. These range from Question Answering services that integrate web search engines with LLMs to a plethora of data-driven chat applications.
Why are AI Enthusiasts still Intrigued by RAG?
RAG has a lot of hidden advantages right from being a cost-effective solution eliminating the need for retraining LLMs to countering hallucinations. Some of the less discussed, yet obvious
- Enhanced Contextual Understanding: RAG leverages retrieved information to provide more contextually relevant responses, improving comprehension and accuracy.
- Dynamic Adaptability: Its integration of search algorithms allows RAG to adapt to evolving data sources, ensuring up-to-date and relevant information.
- Reduced Bias: By drawing from diverse data sources, RAG mitigates the risk of bias inherent in traditional LLMs, fostering more balanced and inclusive responses.
- Improved Answer Quality: RAG’s fusion of search results with LLM-generated responses enhances the overall quality and depth of answers provided.
- Versatile Applications: From question answering to personalized chat interfaces, RAG’s versatility enables a wide range of applications tailored to diverse user needs.
Standard RAG Methodology
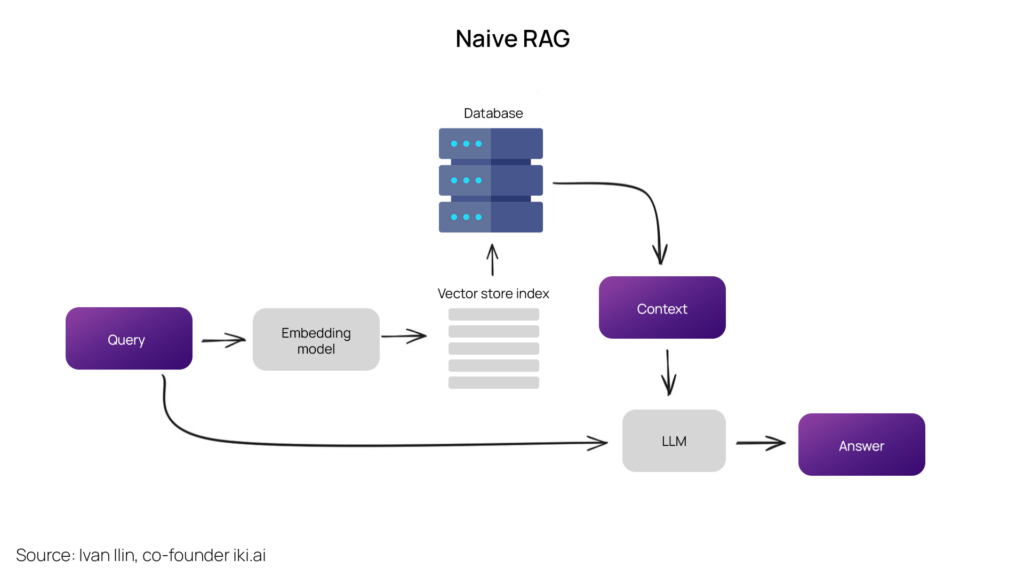
The standard RAG process involves segmenting texts into chunks, embedding these fragments into vectors using a Transformer Encoder model, indexing these vectors, and then crafting a prompt for an LLM. This prompt instructs the model to generate responses based on the user’s query within the context gathered during the search phase.
During runtime, employ the same Encoder model to vectorize the user’s query, conduct a search using this vector against the index, identify the top-k results, retrieve the corresponding text chunks from our database, and use them as contextual input to the LLM prompt.
Did you Know?
Prompt Engineering is the easiest and most cost-effective way to improve RAG pipeline.
Advanced RAG Techniques
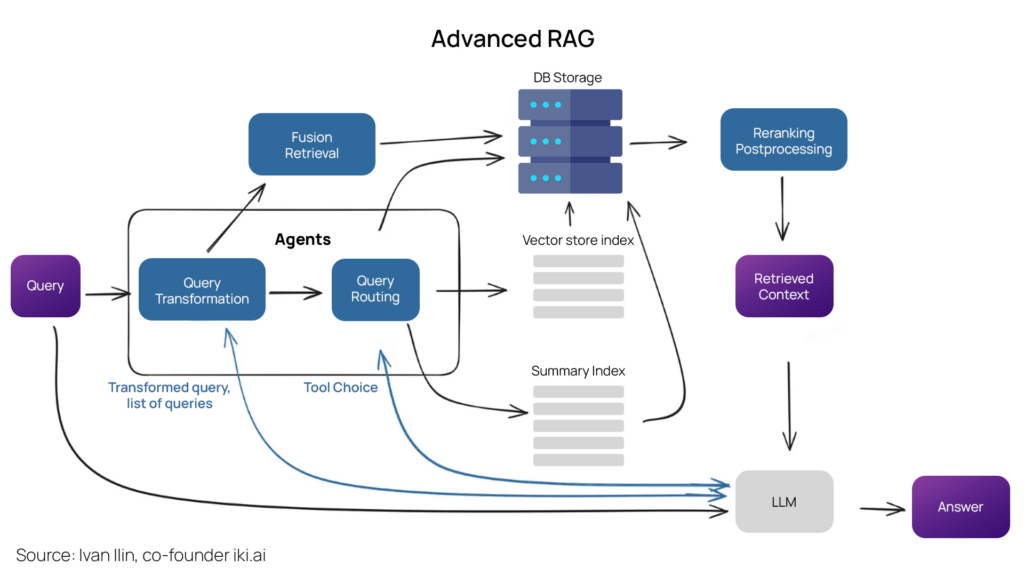
The advanced RAG techniques go one step further than the standard approach. The advanced RAG pipeline is divided into eight major sections. We will explore each of them in detail.
- Chunking & Vectorization
- Search Indexing
- Reranking & Filtering
From query transformation, the following approaches entail intricate logic that leverages LLM reasoning to enhance the effectiveness of the retrieval and generation processes.
- Query Transformations
- Chat Engine
- Query Routing
- RAG Agents
- Response Synthesizers
Check out the overview of the Advanced RAG Architecture for further understanding.
Chunking & Vectorization
Initially, our objective is to construct a vector index representing the contents of our documents. During runtime, our aim is to identify the closest semantic match by searching for the minimum cosine distance between all these vectors and the query vector.
Chunking: Since transformer models operate within fixed input sequence lengths chunking is the way forward. Chunking is the process of partitioning documents into ‘chunks’ of readable sizes. Even with a large input context window, a sentence or a few sentences better encapsulate semantic meaning than a vector averaged over several pages of text. The chunk size is dependent on the embedded model.
The chunk size is a crucial parameter to consider, contingent upon the embedding model’s token capacity. Standard transformer Encoder models, such as BERT-based Sentence Transformers, typically accommodate up to 512 tokens. In contrast, models like OpenAI ada-002 can handle longer sequences, up to 8191 tokens. However, the trade-off lies in balancing sufficient context for the LLM to reason upon versus achieving specific text embedding for efficient search execution. Within LlamaIndex, the NodeParser class handles this aspect comprehensively, offering advanced options such as custom text splitter definition, metadata incorporation, and management of node/chunk relationships.
Vectorization: It refers to the process of converting textual input into numerical representations, or vectors, that the model can process. This conversion allows the LLM to perform mathematical operations on the input, enabling it to understand and generate text. Choosing the right model is an important step as it determines the quality of the output. Search optimized models are a place to start like bge-large or the E5 embeddings family. The latest updates regarding embedding models are available on the MTEB leaderboard.
This complete data ingestion pipeline from LlamaIndex is a very good example for an end-to-end implementation of the chunking and vectorization step.
Search Indexing
The pivotal component of the RAG pipeline entails the search index, which houses the vectorized content obtained in the preceding step. There are different types of search indexing based on the amount and style of information retrieval, the search indexing also changes.
Vector Store Index
The simplest implementation involves a flat index, where a brute-force distance calculation is performed between the query vector and all the vectors of the chunks. However, for efficient retrieval in scenarios with over 10,000 elements, a well-optimized search index, such as a vector index like faiss, nmslib, or annoy leveraging Approximate Nearest Neighbors techniques like clustering, tree, or HNSW algorithms, is preferred.
Additionally, there are managed solutions like OpenSearch or ElasticSearch, as well as vector databases such as Pinecone, Weaviate, or Chroma, which handle the data ingestion pipeline described in the chunking and vectorization step. The index selection, data characteristics, and search objectives may warrant storing metadata alongside vectors. This setup facilitates the use of metadata filters, enabling targeted searches based on criteria such as dates or sources.
Find the list of Vector Store Indices from LlamaIndex here.
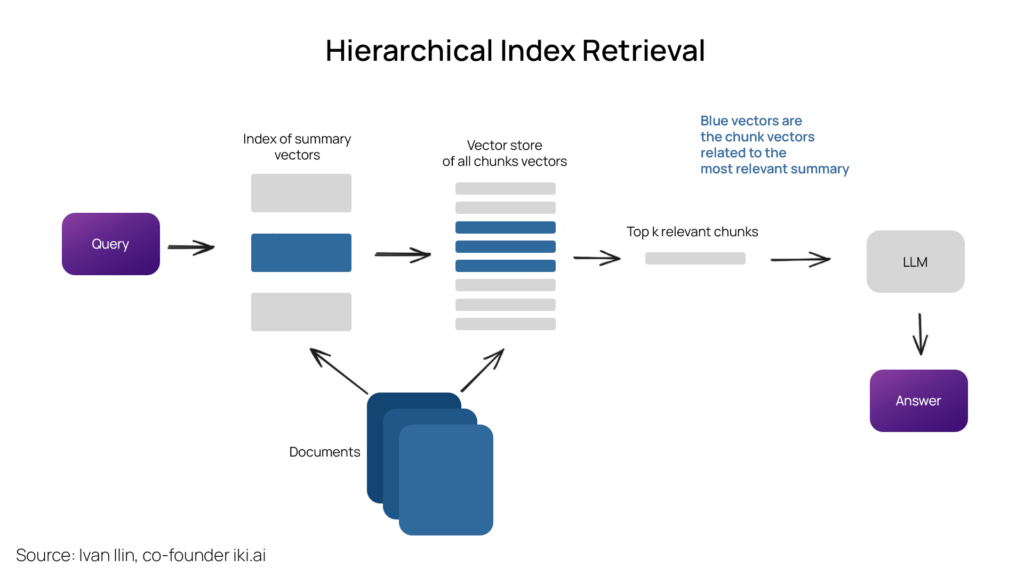
Hierarchical Indices
An efficient approach for large databases with multiple documents involves creating two indices—one comprising summaries and the other comprising document chunks. This entails a two-step search process: first, filtering out relevant documents based on summaries, and then conducting a more focused search within this subset.
Hypothetical Questions
An alternative method involves prompting an LLM to formulate a question for every chunk, embedding these questions into vectors. During runtime, a query search is conducted against this index of question vectors, replacing the chunk vectors with question vectors in our index. Upon retrieval, the original text chunks are routed and provided as context for the LLM to generate an answer. The quality of the search will be better as there is higher semantic similarity between the query and the embedded hypothetical question.
Did you know?
This method is the reverse of another approach called HyDE where the LLM generates a hypothetical response for the query. The response vector in conjunction with the query vector enhances search quality.
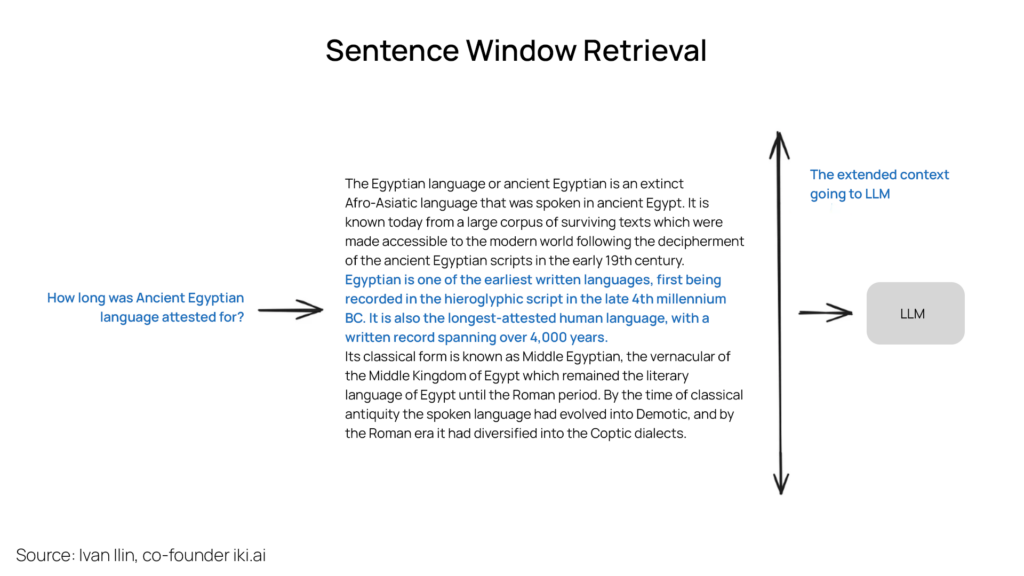
Sentence Window Retrieval
Forms part of the context enrichment approach by retrieving smaller chunks for better quality. Individual sentences within a document are embedded independently ensuring high accuracy in context understanding.
The highlighted text represents the sentence embedding retrieved during the index search. The entire paragraph is then supplied to the LLM, expanding its context for more robust reasoning in response to the given query.
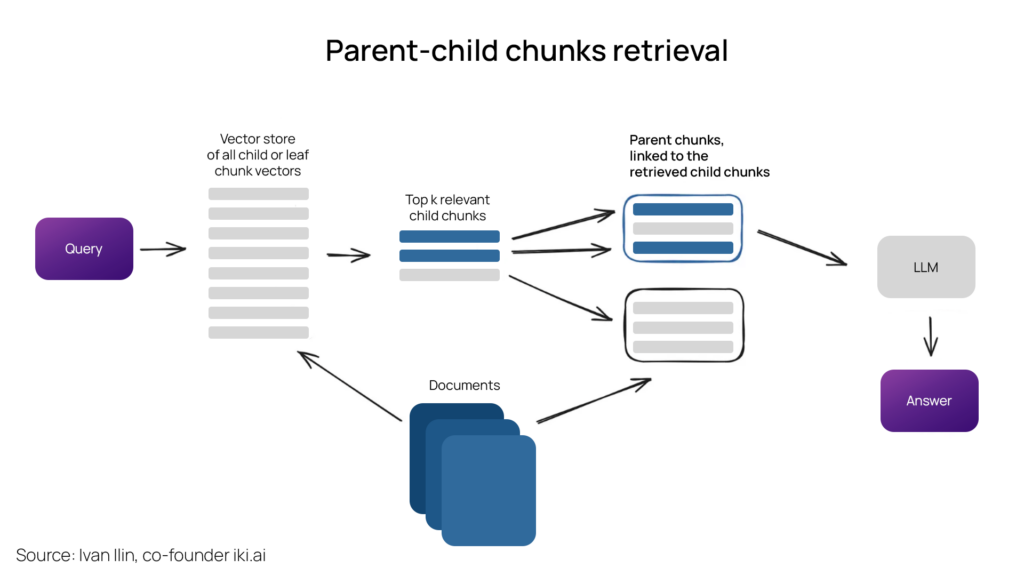
Parent Document Retrieval
This one also forms part of the context enrichment approach by retrieving smaller chunks for better quality. The documents are partitioned into smaller child chunks corresponding to larger parent chunks. Initially, smaller chunks are retrieved during the retrieval process.
If more than y chunks within the top x retrieved chunks are associated with the same parent node (larger chunk), the context provided to the LLM is substituted with this parent node. The search happens within the child nodes. This LlamaIndex tutorial will shed more light into the methodology.
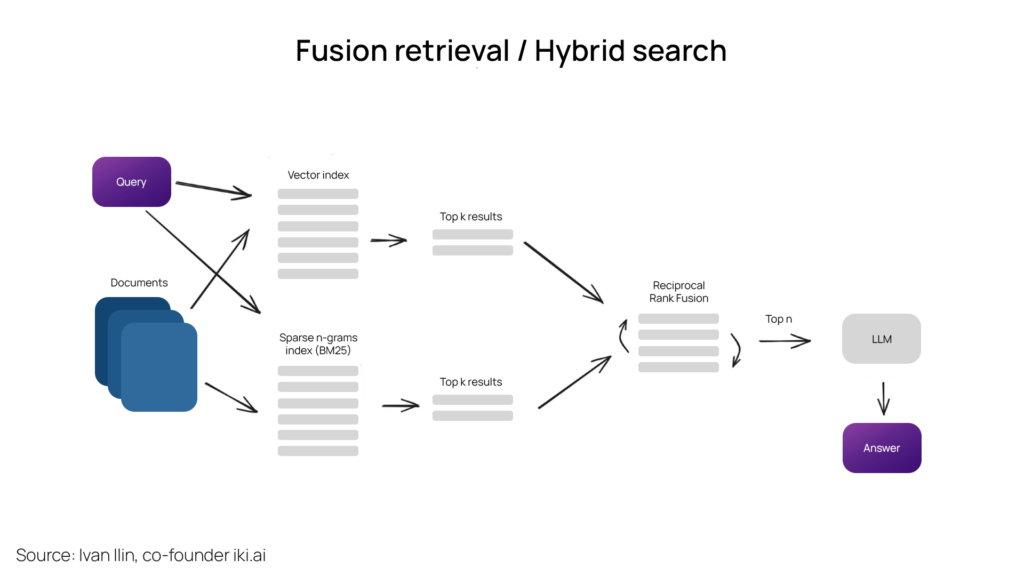
Fusion Retrieval
Hybrid or fusion search typically yields superior retrieval outcomes by combining two complementary search algorithms. This approach considers both semantic similarity and keyword matching between the query and the stored documents, resulting in more comprehensive and accurate results. The result of sparse retrieval methodologies like tf-idf or the more commonly preferred BM25 is combined with the results of a modern semantic or vector-based search and presented as a single result.
To ensure the right retrieval results are combined using different similarity scores, the Reciprocal Rank Fusion method is utilized, which reranks the final result for the retrieved output.
Within LangChain, this functionality is handled in the Ensemble Retriever class. It combines a user-defined list of retrievers, such as a faiss vector index and a BM25-based retriever. It also employs the Reciprocal Rank Fusion (RRF) algorithm for reranking. LlamaIndex also follows a similar approach.
Fusion retrieval results are perceived to be of a higher quality since the results are a combination of two factors – Semantic based search and a keyword-based search thereby enhancing the overall context of the output.
Reranking and Filtering
After obtaining retrieval results using any of the algorithms, the next step involves refining them through filtering, re-ranking, or transformation.
Reranking and filtering in RAG involves refining the retrieved results to enhance their relevance and accuracy. Reranking prioritizes the results based on various criteria, such as semantic similarity or contextual relevance, to ensure the most pertinent responses are presented first. Filtering involves removing irrelevant or redundant results, streamlining the output to focus on the most valuable information. These processes are crucial in optimizing the performance of RAG systems and improving user satisfaction with the generated responses.
LlamaIndex is a goldmine when it comes to reranking and filtering.
- Various Postprocessors filter out results based on similarity scores, keywords, metadata, or rerank them using other models such as an LLM.
- Sentence-transformer cross-encoders for sentence pair scoring and sentence pair classification.
- Cohere reranking endpoint to improve rerank quality
Essentially, LlamaIndex has touched base in their reranking and filtering game.
Now, let’s delve into the more sophisticated RAG techniques, such as query transformation and routing. Both techniques incorporate LLMs, thereby exhibiting agentic behavior within the RAG pipeline.
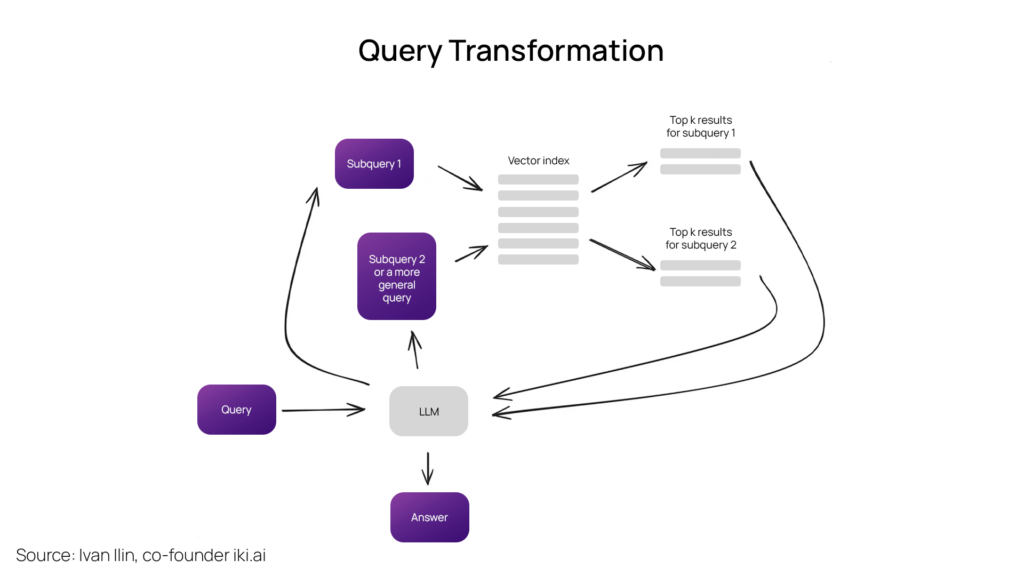
Query Transformations
Query transformations encompass a range of techniques leveraging an LLM as a reasoning engine to enhance retrieval quality by modifying user input. When faced with complex queries, LLMs can decompose them into several sub-queries for more effective retrieval.
For example, “Which biped apes are closer to Homo Sapiens, Chimpanzees or Orangutans?” are broken into two subqueries.
“Are Chimpanzees closer to humans?”
“Are Orangutans closer to humans?”
These sub-queries are executed in parallel, and their retrieved contexts are combined into a single prompt for the LLM to synthesize a final answer to the original query.
These functionalities are available in both LangChain – Multi Query Retriever and LlamaIndex – Sub Question Query Engine.
- Step-back prompting involves using the LLM to generate a more general query, resulting in a broader context useful for grounding the answer to the original query. The original query is retrieved along with feeding both contexts to generate the final answer. The LangChain implementation for Step-back prompting is given here.
- Query re-writing leverages the LLM to reformulate the initial query to enhance retrieval. Both LangChain and LlamaIndex have their own query rewriting implementations, with LlamaIndex’s query rewriting solution being a better one.
Reference citation
Reference citations serve as a crucial tool for accurately attributing sources when multiple sources are used to generate an answer. Since the answer is retrieved from two or more subqueries, reference citation will improve the credibility of the final response by accurately referencing back to its sources and how the context was achieved.
This can be achieved by incorporating referencing tasks into the prompt and instructing the LLM to mention the IDs of the used sources.
Additionally, matching the parts of the generated response to the original text chunks is also considered a way to cite references. LlamaIndex has a powerful solution following Fuzzy logic for reference citations.
Chat Engine
In crafting an effective RAG system capable of sustained interactions for a single query, integrating chat logic becomes paramount, same as in the classic chatbots from the pre-LLM era. This inclusion is essential for supporting follow-up questions, addressing anaphora, or accommodating arbitrary user commands linked to the ongoing conversation context. This challenge is tackled through the query compression technique, which considers both the user query and the chat context to ensure seamless interaction continuity.
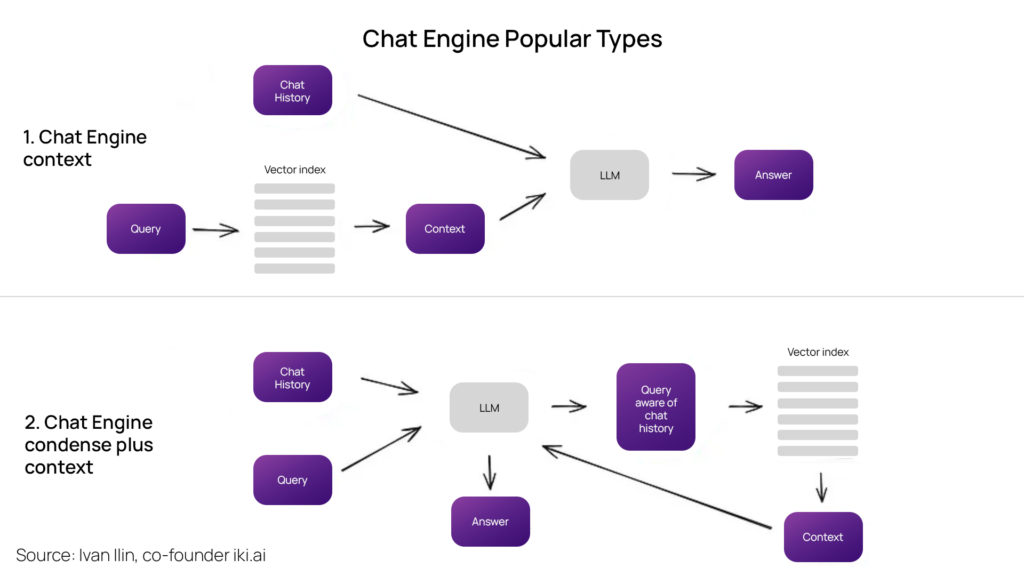
As always, various methods exist for context compression. The more common ones are ContextChatEngine and the CondensePlusTextMode.
Context Chat Engine initially retrieves context pertinent to the user’s query. It then forwards this context, along with the chat history from the memory buffer, to the LLM. This ensures the LLM is cognizant of the previous context when generating the subsequent answer.
A slightly more sophisticated strategy is the Condense Plus Context Mode. Here, during each interaction, the chat history and the last message are condensed into a new query. The condensed query is sent to the index, and a context is retrieved. This retrieved context is passed into the LLM coupled with the original query to generate the response.
OpenAI based chat engines are supported by both LangChain and LlamaIndex. ReAct Agent is another type supported by the LlamaIndex
Query Routing
Query routing is the next step in the RAG pipeline. These typically include summarization, searching against a data index, or exploring various routes before synthesizing their outputs into a single answer.
Query routers play a vital role in selecting the appropriate data store or index to direct the user query. This decision may involve choosing between multiple data sources, such as a vector store and a graph database, or navigating an index hierarchy, such as one comprising summaries and another comprising document chunks vectors for multi-document storage.
The configuration of the query router entails defining the available choices it can make. This selection process is executed through an LLM call, with the result formatted in a predefined manner for routing the query to the designated index. In cases of agnatic behavior, the routing may extend to sub-chains or other agents, as shown in the Multi-documents Agent scheme.
Check out the LlamaIndex and LangChain query routers.
RAG Agents
Since the early days of LLM APIs, Langchain and LlamaIndex have supported the use of agents. The core idea is to equip an LLM, capable of reasoning, with a toolkit and a defined task. These toolkits may include various deterministic functions, such as code functions, external APIs, or interactions with other agents. LangChain is eponymous to the idea of chaining LLMs together.
Agents are a vast subject, but for this guide’s purpose, the discussion will be limited to agent-based multi-document retrieval with the recently revealed OpenAI assistants.
OpenAI Assistants have essentially integrated numerous tools essential for LLM operations that were previously available in open source. These include features such as chat history management, knowledge storage, and document uploading interfaces. Perhaps most notably, they offer a function for calling API, which allows natural language to be translated into API calls for external tools or database queries.
Within LlamaIndex, the OpenAIAgent class integrates advanced logic with the ChatEngine and QueryEngine classes. This combination enables knowledge-based and context-aware chatting, coupled with the capability for multiple OpenAI function calls in a single conversation turn. This integration truly exemplifies intelligent agentic behavior within the system.
The Multi-Document Agents scheme represents a highly sophisticated setup, characterized by the initialization of an agent (OpenAIAgent) for each document. These agents possess capabilities for document summarization and traditional question-answering mechanics. Additionally, a top-level agent is deployed, tasked with routing queries to document agents and synthesizing the final answer.
Each document agent is equipped with two tools: a vector store index and a summary index. Based on the routed query, each document agent determines which index to utilize for processing the query. As for the top agent, all document agents are regarded as tools, collectively contributing to the processing of queries.
Below is an illustration of an architecture with multiple routing decisions made by different agents. Looks like a busy traffic point, huh? The greatest advantage of this approach is its ability to parse through and compare different solutions in different documents and provide a single document summarization.
But like crowded traffic, the responses will be slow due to the multiple back-and-forth iterations in the LLMs. Since the most time-consuming operation in RAG is the LLM – optimizing the search for speed is recommended.
Response Synthesizer
The last step in any RAG pipeline—generating an answer based on the carefully retrieved context and the initial user query. The simplest method involves concatenating and feeding all the fetched context above a preset threshold, along with the query to an LLM at once. However, more sophisticated options exist, including multiple LLM calls to refine retrieved context and generate a superior answer.
Response synthesis can be achieved with three techniques.
- Send the retrieved context chunk-wise into the LLM and refine the answer. This is an iterative process and involves multiple rounds of iterations.
- Take the retrieved context, summarize it, and ensure it fits into the prompt.
- Multiple chunks can generate different answers which are concatenated or summarized at a later stage.
LlamaIndex Response Synthesizer doc contains deeper insights regarding response synthesizing.
Encoder and LLM Fine Tuning
This section will explain how to approach fine tuning of the DL models illustrated in the RAG pipeline. One can fine-tune either the Transformer Encoder, which ensures the quality of embeddings and thus the quality of context retrieval, or an LLM, which is responsible for effectively utilizing the provided context to address user queries. Thankfully, the latter demonstrates proficiency as a few-shot learner, making it suitable for this purpose.
A significant advantage today is the accessibility of advanced LLMs such as GPT-4, which can generate high-quality synthetic datasets. However, it’s important to remain mindful that hastily fine-tuning an open-source model using a small synthetic dataset may limit the model’s overall capabilities. Pre-trained models developed by professional research teams on meticulously collected, cleaned, and validated large datasets offer broader capabilities and reliability.
Encoder fine-tuning
The latest transformer encoders are effectively optimized for search. Ivan Ilin’s performance increase test by finetuning bge-large-en-v1.5 in the LlamaIndex notebook setting demonstrated a 2% retrieval quality increase. A narrow domain dataset in the RAG could benefit with this 2% quality increase.
Ranker fine-tuning
The cross-encoder is already discussed in the reranking section. It can be used to enhance the efficiency of the ranker. The process is as follows: Feed the query and each of the top k retrieved text chunks into the cross-encoder, delineated by a SEP token. Subsequently, fine-tune it to generate a 1 for relevant chunks and a 0 for non-relevant ones. Learn more about how to finetune the ranker with this LlamaIndex guide to experience a 4% increase in the quality.
LLM fine-tuning
OpenAI’s approach to LLM finetuning is by generating the questions using GPT 3.5 Turbo and letting GPT-4 generate responses for those questions. Then fine-tune GPT 3.5 with the dataset of the question-answer pairs. This improvement achieved through a ragas framework, showcased a 5% increase in the faithfulness metrics, thus proving that GPT 3.5’s contextual understanding improved significantly with the RAG pipeline. Learn about LlamaIndex’s approach to finetuning GPT 3.5 Turbo here.
A more sophisticated approach is illustrated in the recent paper by Meta AI Research. This technique proposes tuning both the LLM and the Retriever (a Dual Encoder in the original paper) on triplets of query, context, and answer. For implementation details, please refer to the guide provided. This technique has been employed to fine-tune both OpenAI LLMs through the fine-tuning API and the Llama2 open-source model, resulting in approximately a 5% increase in metrics for knowledge-intensive tasks (compared to Llama2 65B with RAG) and a few percentage points increase in common sense reasoning tasks.
Evaluation
Various frameworks exist for evaluating the performance of RAG systems, typically comprising separate metrics such as overall answer relevance, answer groundedness, faithfulness, and retrieved-context relevance. Ragas, as discussed earlier, employs faithfulness and answer relevance as metrics for assessing the quality of generated answers, along with classic context precision and context recall for evaluating the retrieval aspect of the RAG scheme.
AndreNG amd LlamaIndex mention the RAG triad which consists of retrieved context relevance, groundedness (LLM relatability to the provided context), and the answer relevance of the generated response.
The retrieved context relevance can be controlled with the Advanced RAG techniques mentioned from Chunking till employing RAG agents along with encoder and ranker fine tuning. Response synthesizer along with LLM fine tuning can improve the groundedness and answer relevance. A simple example of retriever evaluation pipeline applied to the encoder fine tuning section can be accessed by clicking here.
A more nuanced approach, as demonstrated in the OpenAI cookbook, goes beyond merely considering the hit rate and incorporates metrics such as Mean Reciprocal Rank, a common search engine metric. Additionally, this approach considers metrics for generated answers, such as faithfulness and relevance.
LangChain boasts an advanced evaluation framework called LangSmith, which allows for the implementation of custom evaluators. Additionally, LangSmith monitors the traces within the RAG pipeline, enhancing transparency and enabling a deeper understanding of system operations.
LlamaIndex also provides a rag evaluator pack, to evaluate the pipeline with public datasets.
How ParrotGPT Leverages RAG to Improve Response Context
ParrotGPT leverages the RAG model to ensure the response generated stays within its context. The first step ParrotGPT takes is to break the document or content into manageable chunks and store it in different locations. The Chunk size is determined by the size of the content to be trained, but it never exceeds the 250-word per chunk mark. When RAG receives a prompt, it identifies the relevant chunk r chunks and passes it on to the LLM for it to generate its answer. The chunks to be passed are identified with the distance between the scores to ensure the context of the response is not lost.
ParrotGPT’s RAG model ensures that LLM does not hallucinate and provides a response that’s the opposite of the question asked. It can work with any LLM be it Meta’s Llama or Open AI’s GPT, even a private LLM. The model continuously learns itself and updates with the most recent answer.







