Introduction
We discussed about the fundamentals of an Apache Spark system including its architecture in the previous blog. We shared the basic differences between Resilient Distributed Datasets and Dataframes. We’ve covered the what and the why, now we are going to discuss about the how. This blog will outline the different steps involved in an Apache Spark Program execution. But before knowing about Spark execution, we need to understand what is a DAG.
Understanding Directed Acyclic Graphs (DAG)
Spark translates any RDD’s into DAG (Directed Acyclic Graph) or when any action is done on an RDD spark submits the operator graph to the DAG scheduler. DAG is nothing but a graph that holds the track of operations (Transformations or Actions) applied on RDD. These advantages of building the DAG helped in overcoming the drawbacks of Hadoop MapReduce.
Directed
This means that is directly connected from one node to another. This creates a sequence i.e. each node is in linkage from earlier to later in the appropriate sequence.
Acyclic
Defines that there is no cycle or loop available. Once a transformation takes place it cannot return to its earlier position.
Graph
From graph theory, it is a combination of vertices and edges. Those pattern of connections together in a sequence is the graph.
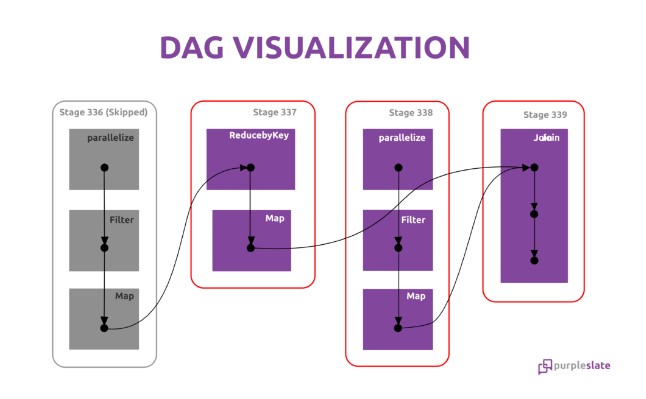
Directed Acyclic Graph is an arrangement of edges and vertices. In this graph, vertices indicate RDDs, and edges refer to the operations applied on the RDD. It flows in one direction from earlier to later in the sequence. When we call an action, the created DAG is submitted to DAG Scheduler. That further divides the graph into the stages of the jobs.
Decoding Spark Program Execution
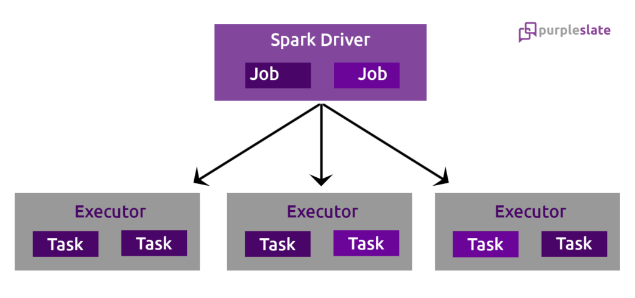
All the operations (transformations and actions) are arranged further in a logical flow of operations, that arrangement is DAG. DAG graph converted into the physical execution plan which contains stages. After all, DAG scheduler makes a physical execution plan, which contains tasks. Later on, those tasks are joined to make bundles and send over to the cluster. Divide the operators into stages of the task in the DAG Scheduler. A stage contains a task based on the partition of the input data. The DAG scheduler pipelines operators together. For example, map operators schedule in a single stage.
The stages pass on to the Task Scheduler. It launches tasks through cluster manager. The dependencies of stages are unknown to the task scheduler. The Workers execute the task on the slave. When any node crashes in the middle of any operation that depends on another operation, the cluster manager finds the node is dead and assigns another node to continue processing. Now there will be no data loss and will be fault-tolerant. After workers execute the tasks it is passed back to the Driver node for completion. The entire operation is visualized in the below given diagram.
Summing up
This concludes our blogs in the Apache Spark series. To refresh your memory our first blog on the series talks about what is Apache Spark, what are some of its alternatives and how it’s different from Hadoop, another famous data processing framework.
The second blog discusses in detail the architecture of Apache Spark, breaks down to the detail of what are RDDs and Dataframes. The third and final blog outlines how to execute an Apache Spark program. We hope that you were able to get a complete picture of Apache Spark as a data processing engine. We will keep posting educational blogs in this section to empower the young techies interested in Data engineering, Data analytics and Data Visualization. Stay tuned to this space, folks!