Introduction
The previous blog, we saw about what is Apache Spark & how it is a preferred data analysis engine due to the speed it possesses. This blog is where we discuss about the intricacies of Apache spark’s working principle and we will introduce the concept of Spark RDD’s and data frames.
Breaking the Class – The Driver and Worker Node Relation
Any big data platform which handles huge volumes of data involves processing the data on a set of processing nodes called a cluster. Processing of data is typical ETL (Extract from source, Data Transformation into desired consumption format and structure and Loading into the storage) pipelines.
Typical Apache Spark cluster consist of “Driver” and “Executor / Worker” nodes.
Driver Node
Driver Node is the link between the users and the physical computations required to complete or process a task. A driver node has its own set of memory, CPU, and cache but the role of that is to host the wider cluster.
Worker Node
Worker nodes aid the execution of the tasks assigned to the entire cluster. They are also stand-alone machines with their own hardware components. The major difference between a driver and worker node is that these memory components are used to execute the task as opposed to hosting the cluster.
The below diagram depicts a typical spark cluster.
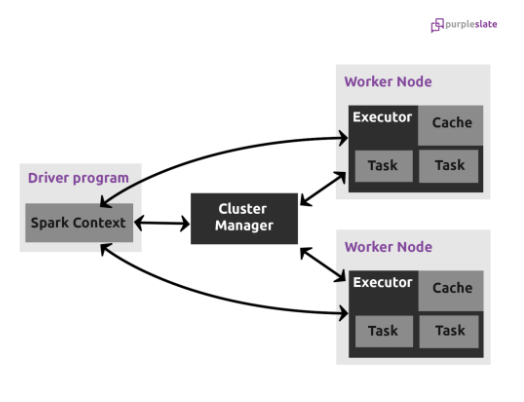
There will be only one Driver node and more Worker nodes in a cluster. During the creation of the cluster one can define the cluster size (CPU’s and memory), autoscaling options, minimum and maximum number of worker nodes that it can spawn during the execution. All Spark components, including the Driver, Master, and Executor processes, run in Scala and Java virtual machines (JVMs).
The Driver and Worker Node Responsibility Matrix
Now that you’ve a clear understanding of what’s a driver node and a worker node, and how it fits inside the cluster, we will discuss about what are the responsibilities of a driver and a worker node.
| Responsibilities of Driver | Responsibilities of Worker / Executor |
| The main() method of our program (Scala, Java, Python) runs in the Driver process. It creates SparkSession or SparkContext. SparkSession is responsible to create DataFrame, DataSet, RDD, execute SQL, perform Transformation & Action, etc. | Executes all the tasks that were scheduled by the Driver |
| Depending on the spark program, finds and decides possible number of tasks with help of lineage, and execution plans (logical and physical). | Cache data in the worker node. |
| Helps to create the Lineage, Logical Plan and Physical Plan | |
| Schedules the execution of tasks by co ordinating with the cluster manager (Cluster Manager keeps track of the available resources (nodes) available in the cluster). | |
| Coordinates with all the Executors for the execution of Tasks. It looks at the current set of Executors and schedules our tasks. | |
| Keeps track of the data (in the form of metadata) that was cached (persisted) in Executor’s (worker’s) memory. |
Back to the Basics – Spark RDD (Resilient Distributed Dataset)
RDD is the fundamental Data structure of Apache Spark. It is a collection of objects and is capable of storing and processing as partitioned data split across multiple nodes in the cluster. It has no schema. Whether you use Dataframe or Dataset, all your operations eventually get transformed to RDD. RDD API provides many actions and transformations.
Actions
Transformations create RDDs from each other, but when we want to work with the actual dataset, at that point action is performed. When the action is triggered after the result. Thus, Actions are Spark RDD operations that give non-RDD values. The values of action are stored to drivers or in the external storage system. It brings the laziness of RDD into motion.
Action is one of the ways of sending data from the Executor to the driver. Executors are agents that are responsible for executing a task. While the driver is a Java Virtual Machine (JVM) process that coordinates workers and execution of the task. Actions include count(), collect(), take(n), top(), count value(), reduce(), fold(), aggregate(), foreach()
Transformation
Transformation includes functions like map(), filter(),join(),union(),coalesce() and reduce() etc. for performing computations on Data. Transformation is a function that produces new RDD from the existing RDDs. It takes RDD as input and produces one or more RDD as output. Each time it creates a new RDD when we apply any transformation. Thus, the so-input RDDs, cannot be changed since RDD are immutable. Transformations are lazy in nature i.e., they get executed when we call an action. They are not executed immediately. There are 2 types of transformations
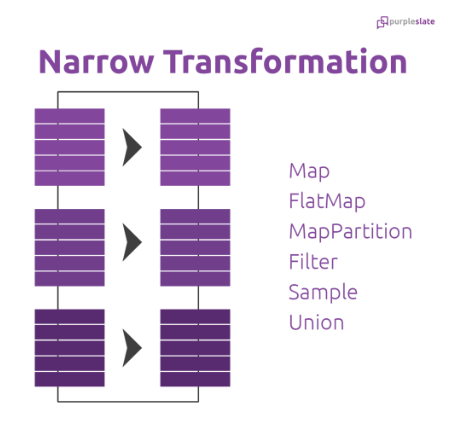
Narrow Transformation
In Narrow transformation, all the elements that are required to compute the records in a single partition live in the single partition of parent RDD. Doesn’t require the data to be shuffled across the partitions. A limited subset of partition is used to calculate the result. Narrow transformations are the result of map(), filter().
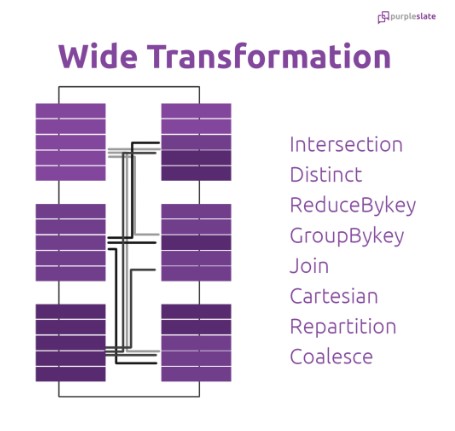
Wide Transformation
In wide transformation, all the elements that are required to compute the records in the single partition may live in many partitions of parent RDD. The partition may live in many partitions of parent RDD. requires the data to be shuffled across partitions. Wide transformations are the result of groupbyKey() and reducebyKey().
Back to the Basics – Spark Dataframe
Spark Dataframes are the distributed collection of the data points, but here, the data is organized into the named columns. They allow developers to debug the code during the runtime which was not allowed with the RDDs. Dataframes can read and write the data into various formats like CSV, JSON, AVRO, HDFS, and HIVE tables. It is already optimized to process large datasets for most of the pre-processing tasks so that we do not need to write complex functions on our own. The below table outlines the fundamental differences between an RDD and a dataframe.
| RDD () | Dataframe |
| RDD is a distributed collection of data elements spread across many machines in the cluster. RDDs are a set of Java or Scala objects representing data. | A DataFrame is a distributed collection of data organized into named columns. It is conceptually equal to a table in a relational database. |
| Can process structured as well as unstructured. Schema-less. | Can process structured and semi-structured only. Requires schema |
| Data source API allows that an RDD could come from any data source e.g. text file, a database via JDBC, etc., and easily handle data with no predefined structure. |
Data source API allows Data processing in different formats (AVRO, CSV, JSON, and storage system HDFS, HIVE tables, MySQL). It can be read and written from various data sources that are mentioned above. |
| RDDs contain the collection of records that are partitioned. The basic unit of parallelism in an RDD is called partition. Each partition is one logical division of data that is immutable and created through some transformation on existing partitions. Immutability helps to achieve consistency in computations. We can move from RDD to DataFrame (If RDD is in tabular format) by toDF() method or we can do the reverse by the .rdd method. | After transforming into a DataFrame one cannot regenerate a domain object. For example, if you generate testDF from testRDD, then you won’t be able to recover the original RDD of the test class. |
| No inbuilt optimization engine is available in RDD. When working with structured data, RDDs cannot take advantage of spark’s advanced optimizers | Optimization takes place using catalyst optimizer. Dataframes use catalyst tree transformation framework in four phases: a) Analyzing a logical plan to resolve references. b) Logical plan optimization. c) Physical planning. d) Code generation to compile parts of the query to Java bytecode. |
Now that you’ve understood what are the key components in an Apache Spark system, we will discuss about how Apache spark programs are executed in the next blog. Until then, stay tuned folks!